Unicode和它的朋友们(下)
Author: [麟十一]
Link: [https://mp.weixin.qq.com/s/7kyZVkAgeU3FjkmLAds_Jw]
8. Unicode和ISO 10646
在世界各国都有了自己的编码后,另一个问题出现了,由于各个字符集的字符和编码不同,想要同时使用不同语言输出不同字符变得非常困难,而且在转换不同语言的文件时很容易出现乱码。为了解决这些问题,字符编码进入了第三个阶段:全球化
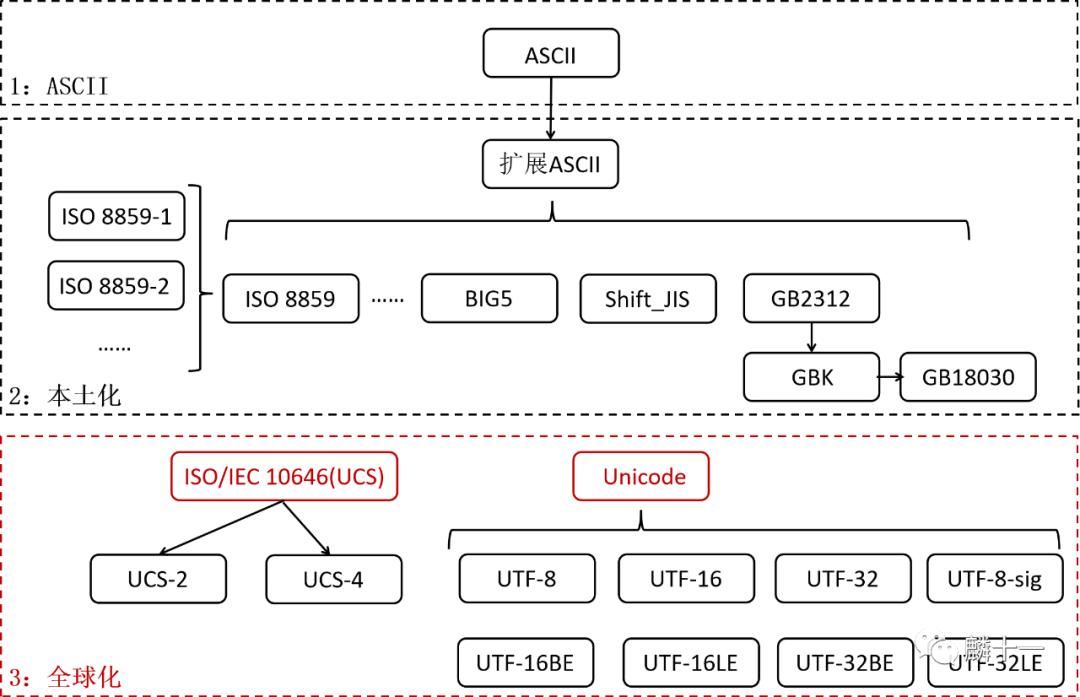 第三阶段:全球化--
第三阶段:全球化--UCS和Unicode
8.1 ISO 10646和Unicode
ISO/IEC10646(JTC1/SC2/WG2) ,简称ISO 10646 。是由国际标准化组织(ISO)和国际电工委员会(IEC)中的联合技术委员会#1(Joint Technical Committee#1, JTC1),附属委员会#2(Subcommittee #2, SC2)和工作组#2(Working Group #2, WG2)制订的。ISO 10646全称为通用多八位编码字符集(Universal Multiple-Octet Coded Character Set)或者通用字符集(Universal Character Set, UCS)。这个字符集给世界上各种语言的每个字符都赋予了唯一的编码,以满足跨语言、跨平台的文本信息转换。
而另一个组织统一码联盟(The Unicode Consortium) 当时也在做同样的事情,他们定义的字符集叫做Unicode ,中文也被称为统一码,万国码,单一码。ISO/IEC创建于1984年,统一码联盟创建于1988年。
最初,两个组织为各自的字符集定义了不同的编码标准,但是很快他们就发现对方在做同样的事情,所以两个组织从1991年开始共享合作成果并且共同扩展编码标准,使得各自的字库、编码保持同步 。虽然两个字符集的编码和字符完全相同,但他们是独立存在 的,也一直在更新自己的版本。两个字符集之间也有着细微的差异,比如二者部分样例字形有区别,Unicode增加了一些语言细节处理算法等等。不过这两个字符集在日常应用中并没有区别,Unicode的名气更大一些。
任何字符在Unicode或者ISO 10646中都对应着唯一的编码值,这个值被称作代码点/码位(Code Point) 。由于Unicode(ISO 10646)创立了一套新的编码标准,所以它与GB系列的编码不兼容 ,有些实现方式(UTF-8)与ASCII兼容,有些(UTF-16, UTF-32)不兼容。
8.2 代码页的问题
另外,随着Unicode在Windows中的应用,Windows代码页逐渐被取代,因为所有字符都被包含在了一个字符集中,不再需要通过查找代码页输出不同的字符。不过目前代码页在Windows和其他平台上依旧可以得到支持,在代码页中也能找到UTF-8,UTF-16对应的编号(UTF的内容在第9节)。可以说代码页和Unicode属于 “你中有我,我中有你” 的关系,代码页包括了Unicode字符集的各种实现方式,Unicode也包括了代码页中所有字符集的字符 。
8.3 字符集的发展历史
最后说一下两个字符集的发展和合并历史,这和下一部分的内容是有联系的(注意:以下提到的只是其中一部分版本)。Unicode第一个版本叫Unicode1.0,发布于1991年10月,共收录7161个字符,Unicode1.0不包括CJK(中日韩)字符。1993年CJK字符集制订完成,ISO和Unicode在同一年都发布了各自的版本:ISO 10646-1:1993和Unicode 1.1。ISO 10646-1:1993对字符进行了两种形式的编码:UCS-2和UCS-4,UCS-4定义的字符更多一些(UCS的内容在第9节),这里只需要知道Unicode1.1和ISO 10646-1:1993中UCS-2的代码点完全相同 就可以了。
Unicode2.0于1996年7月发布,共收录38950个字符,在这之前,ISO 10646-1:1993还发布了一些修订版,从Unicode2.0开始,Unicode采用了和ISO 10646-1:1993完全相同的字库和字码,也就是加入了UCS-4定义的字库 。而ISO也承诺,ISO 10646不会给超出0x10FFFF(1114111)的UCS-4编码赋值 ,使得二者字符集保持一致。所以从这时候起,二者才真正保持了一致,并且在之后的版本中也一直保持着同步更新。这一段的内容和下一节会有联系,在9.2中也会解释这段话的含义。
9. UCS-2,UCS-4和UTF
 第三阶段:全球化--
第三阶段:全球化--UCS-2,UCS-4和UTF
接下来讲一讲ISO 10646(UCS)和Unicode这两个字符集是如何对字符进行编码的。先讲一个概念,编码形式 ,简单来说它是给每个字符赋予的数值形式 ,前文GBK的编码形式就是一个汉字对应两个字节(16位二进制数字)。
9.1 UCS和UCS-2,UCS-4
ISO 10646(UCS)有两种字符编码形式,一种叫UCS-2(Universal Character Set Coded in 2 Octets),一种叫UCS-4(Universal Character Set Coded in 4 Octets)。UCS-2使用2个字节定义一个字符** ,范围是0-0xFFFF(0-65535),UCS-4使用4个字节中的低31位定义一个字符,最高位为0 ,范围是0-0x7FFFFFFF(0-2147483647)。
9.2 Unicode和UTF
Unicode中主要有三种编码形式,分别为 (8-bit Unicode Transformation Format), (16-bit Unicode Transformation Format)和(32-bit Unicode Transformation Format)。UTF-32使用32位来编码字符 ,UTF-16和UTF-8都属于变长 的字符编码,UTF-16使用16位或32位对字符编码,UTF-8使用8-32位对字符编码 。
Unicode的字符范围为**0-0x10FFFF(0-1114111)** ,这就是上一节中“ ISO也承诺,ISO 10646不会给超出0x10FFFF(1114111)的UCS-4编码赋值 ”含义所在。由于ISO 10646-1:1993中定义的UCS-4范围是0-0x7FFFFFFF(0-2147483647),远远超过Unicode定义的字符范围,为了保持二者字符集的同步 ,ISO决定不给超出Unicode字符范围的编码赋值,使得两个字符集的范围都是0-0x10FFFF(0-1114111)。
上文总共提到5种编码方式,可以发现UCS-2和UTF-16都使用16位来编码字符(UTF-16还可以用32位),UCS-4和UTF-32都使用32位来编码字符,这两对编码方式之间也是有联系的。
9.3 UCS-2和UTF-16
UTF-16被正式定义于ISO 10646的附录中,后被Unicode所使用,UTF-16可以看作UCS-2的父集 ,在没有补充平面只有第零平面的时候,UTF-16和UCS-2是一个意思,都使用16位来编码字符。在出现了补充平面之后,UCS-2就被UTF-16替代了,因为UCS-2不支持超过2字节的字符,而UTF-16可以用32位来编码补充平面上的字符 。目前UCS-2使用的非常少,有关第零平面和补充平面的内容在9.5。
9.4 UCS-4和UTF-32
UTF-32可以看作UCS-4的子集 ,9.2中说过,UCS-4定义的代码点远超Unicode的代码点,所以在Unicode的范围内,UCS-4和UTF-32表示的字符是相同的 。而超出Unicode范围的代码点目前并没有定义过任何字符,所以目前可以认为UCS-4和UTF-32是一回事。
9.5 第零平面和补充平面
接下来讲刚刚提到的第零平面和补充平面,这个和Unicode存储字符的方式有关。在6.1 GB2312中提到过,GB2312将存储的汉字分为了94个区,每个区有94个位,Unicode也是用这种方法存储的字符。Unicode将1114112(0-1114111)个码位分成了17个区(平面),每一个区包含65536个码位 。我们常用的字符几乎都存储在第零平面(Plane 0) 中,全称为基本多文种平面(Basic Multilingual Plane, BMP),编码范围 。其他的16个平面被称为补充平面(Supplementary Planes,SMP )。UCS-2只能表示第零平面的字符,其他4种编码方式可以表示所有平面的字符。来看一张第零平面的示意图:
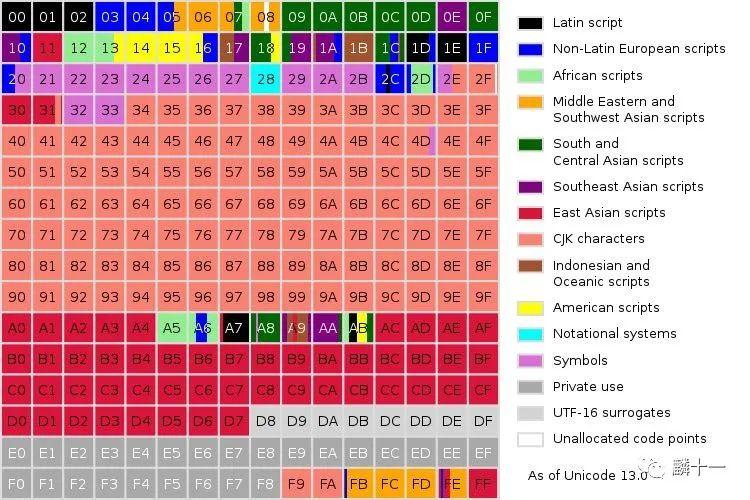 第零平面示意图
第零平面示意图
上图不同颜色就代表了不同语言在第零平面上占据的码位,其中粉色“CJK characters”就是中日韩文字的码位了,可以看到还是占据了非常大的一部分。接下来看一张Unicode中所有平面的示意图:
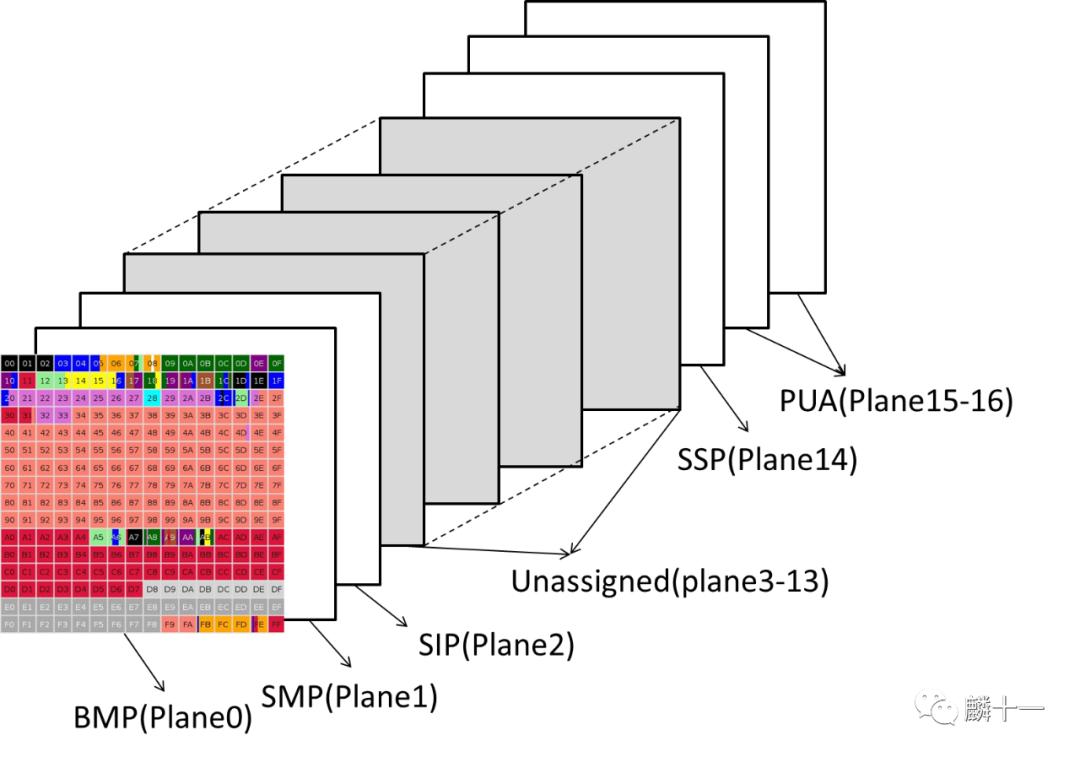
Unicode所有平面示意图
除了第零平面,其他平面使用的较少,第一平面叫做多文种补充平面(Supplementary Multilingual Plane, SMP),主要包括古文字,专用文字如音乐标记、Emoji表情等。第二平面叫表意文字补充平面(Supplementary Ideographic Plane, SIP),主要对CJK字符进行补充。第三平面叫表意文字第三平面 (Tertiary Ideographic Plane, TIP),计划 摆放甲骨文、小篆、中国战国时期文字等。第三平面在上图中并未显示,因为从第三平面到第十三平面都尚未开始使用 。第十四平面叫特别用途补充平面(Supplementary Special-purpose Plane, 简称SSP),主要存储控制字符。第十五和第十六平面是私人使用区(Private Use Areas, PUA)。
10. UTF-8,UTF-16,UTF-32
最后讲UTF-8,UTF-16和UTF-32,刚刚我们提到的Unicode和UCS字符集,仅仅规定字符和数值之间的对应关系,没有规定数值如何在电脑中存储 。例如“麟”的Unicode编码为“U+9E9F”(Unicode字符集中字符编码格式为“U+十六进制数 ”),9E9F转化为二进制共有16位,需要用两字节来表示,其他字符可能会需要更多字节。那么当计算机遇到这样一串数值之后如何知道这几个字节表示的是一个字符,而不是多个单字节的字符呢?这就是UTF的用处。它规定了数值在计算机中进行存储的方式。可以认为**UTF-8,UTF-16和UTF-32是Unicode的具体实现方式** ,当然还有UTF-7这样的实现方式,但是这里只讨论最常见的三种。
10.1 UTF-8
UTF-8是一种可变长度 的编码方式,使用1-4个字节 表示一个符号,它的编码规则有两条。第一:对于单字节字符,最高位为0,低7位为Unicode二进制数值 ,所以对于英文字符,UTF-8编码值和ASCII相同,也就是说,UTF-8兼容ASCII 。第二:对于n字节(n >1)字符,第一字节高n位为1,高n+1位为0,后面字节高2位为10,剩下的字符为Unicode二进制数值。
贴一个官网问答页面,里面包含了有关Unicode的各种问题及解答,非常详细: _http://www.unicode.org/faq/_ 。我从这个网址的文件中截取了一张UTF-8编码的示意图,光看这个图可能有些不好理解:
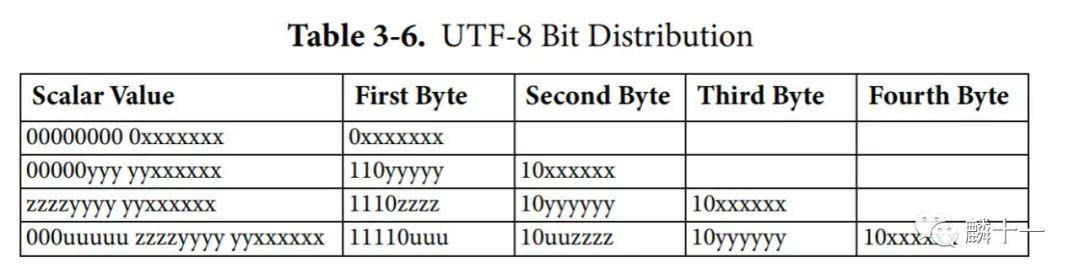 官网
官网UTF-8编码示意表
我又做了一张表解释上面的图,根据Unicode不同代码点的范围,UTF-8会将Unicode字符编成不同长度的字节,而每一个字节高位中1和0的组合,就是计算机识别UTF-8编码的标识符 。从下表可以发现,第一字节中1的数量就等于字节的长度。如果1的数量为0,就说明是ASCII编码。所以当计算机遇到这样一串数值时,就能根据首字节中的数值判断出共有几个字节:

UTF-8编码示意表
还是举“麟”的例子,Unicode代码点为“U+9E9F ”,范围在上表第三行U+0800-U+FFFF之间,使用三个字节对字符进行编码。具体转换过程如下图:
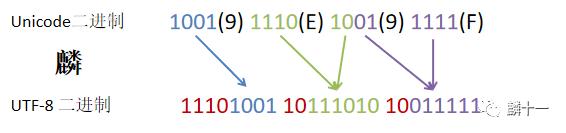
“麟” UTF-8转换示意图
这样一看还是很简单的,使用Python验证一下:
#对'麟'使用`UTF-8`编码
char = '麟'.encode('`utf-8`')
print(char) # b'\xe9\xba\x9f'
#编码长度
len(char) # 3
#查看每个字节的编码
byte1 = bin(char[0])
byte2 = bin(char[1])
byte3 = bin(char[2])
print('`UTF-8`编码为: {}'.format(byte1[2:] + ' ' + byte2[2:] + ' ' + byte3[2:]))
#`UTF-8`编码为: 11101001 10111010 10011111和0x代表十六进制一样,0b代表二进制,有关如何使用Python对不同进制、Unicode字符进行转换,文章第12节会具体展示。
10.2 UTF-16-数值层面
UTF-16也是一种变长 的编码方式,使用16或32位(2或4个字节) 表示字符,对第零平面中的字符使用2个字节编码,对补充平面的字符使用4个字节编码 。由于UTF-16对英文字符也使用2字节编码,所以UTF-16不兼容ASCII ,而且原本只需要一字节就能表示的字符,UTF-16需要两字节,所以它占用的存储空间也比较大。先放上官网中UTF-16编码的示意表:

官网UTF-16编码示意表
上表中,如果字符在第零平面 中(范围U+0000-U+FFFF),Unicode十六进制数值就是UTF-16的编码值 。而在补充平面 中(范围U+10000-U+10FFFF)编码会复杂一些。
从表格中可以看到,在对补充平面字符 进行编码时,Unicode十六进制数值长度为24位并且高3位都是0,这是为什么?前文提到过,Unicode编码的范围是U+0000-U+10FFFF,也就是说Unicode十六进制数值最长只有21位。而电脑在处理数据时一般都会读取8的倍数位(1字节=8比特),这里就是3*8=24位,所以填补0的过程相当于模拟电脑处理数值的过程,先将高位都填补为0使得Unicode二进制数值长度为24位 。举个例子,假如字符只有17位二进制数值,那就需要将高7位都填补为0,如果有20位,就将高4位填补为0。
填补之后,需要将高4-高8位(uuuuu)删去最低位变成wwww,结合剩下的所有数值填补进UTF-16编码除固定数值之外的位置中 。这里的固定数值就是下表中第一字节的1101 10和第三字节的1101 11。我把上一张表换了一个方式表达,把每一个字节分开显示,这样更容易理解一些:

UTF-16编码示意表
先举一个第零平面字符的例子,非常简单,拿“麟”-“U+9E9F”举例,直接将Unicode的十六进制数值转换成二进制 就可以了:

第零平面字符用UTF-16BE编码示意图
再举两个补充平面字符的例子,第一个Emoji表情的Unicode编码为“U+1F604 ”,第二个CJK兼容象形文字的Unicode编码为“U+2FA02 ”。由于字符在这里显示不出来,所以相应字符和转换步骤都在下图:
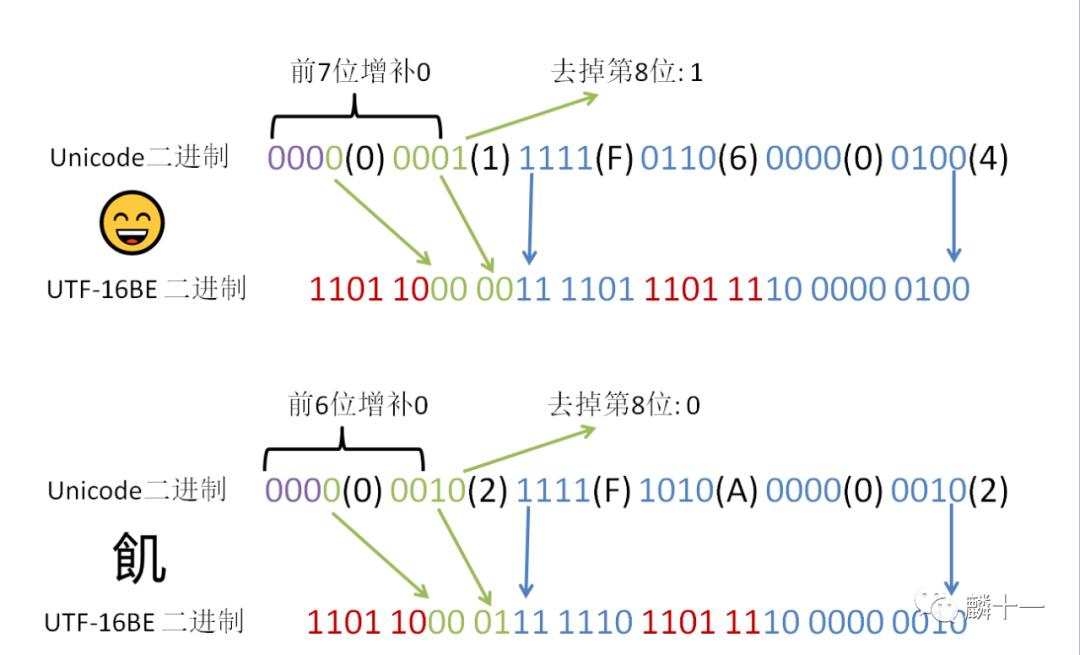 补充平面字符使用
补充平面字符使用UTF-16BE编码示意图
使用Python验证一下(检查的时候发现象形文字在代码中也显示不出来):
# 自定义一个打印函数
def Printbyte(char, UTF_type):
'''打印字符的UTF编码、编码长度和每字节的二进制数值'''
char_byte = char.encode(UTF_type)
#1. 字符编码
print(char_byte)
#2. 编码字节长度
print(len(char_byte))
#3. 每个字节二进制数值
for i in range(len(char_byte)):
bin_char = bin(char_byte[i])[2:] # 取出每个字节的二进制数值
if len(bin_char) != 8:
#如果不足8位,高位补0后输出
add0 = '0'* (8-len(bin_char))
print('第' + str(i+1) + '字节: ' + add0 + '{}'.format(bin_char))
else:
#如果8位,直接输出
print('第' + str(i+1) + '字节: {}'.format(bin_char))
#1. 麟
Printbyte('麟', '`utf-16`BE')
#1.1 编码内容 b'\x9e\x9f'
#1.2 编码字节长度 2
#1.3 每字节的二进制数值
#第1字节: 10011110 第2字节: 10011111
#2. Emoji
Printbyte('😄', '`utf-16`BE')
#2.1 编码内容 b'\xd8=\xde\x04'
#2.2 编码字节长度 4
#2.3 每字节二进制数值
#第1字节: 11011000 第2字节: 00111101 第3字节: 11011110 第4字节: 00000100
#3. CJK兼容象形文字
Printbyte('飢', '`utf-16`BE')
#3.1 编码内容 b'\xd8~\xde\x02'
#3.2 编码字节长度 4
#3.3 每字节二进制内容
#第1字节: 11011000 第2字节: 01111110 第3字节: 11011110 第4字节: 00000010代码和图片中出现的UTF-16BE在11.2中会讲到。
10.3 UTF-16-字符集层面
** **
刚刚的转换方式我们只停留在了数字层面,就是只做了一个数字转换的工作,那么UTF-16在字符集层面是如何转换的呢?这里需要用到之前提到过的基本多文种平面(BMP) 。在9.5中的BMP示意图中我们看到有一块灰色的区域(D8-DF)是用于**UTF-16 surrogates(UTF-16代理)** ,这一部分就是UTF-16利用BMP并使用代理对(Surrogate Pair) 的方式对字符进行编码的地方。

BMP中的UTF-16代理区域
补充平面中的码位会被UTF-16编码成一对16bit长的码元(Code Unit) ,这两个码元就是代理对 。那么什么是码元?简单来说码元是一种信息量的载体,它是一个包含一定信息量的单位 。在UTF-8中,1码元包含8bit(1字节)的信息, UTF-16中包含16bit(2字节)的信息,UTF-32中包含32bit(4字节)的信息。
UTF-16在编码补充平面的字符时,会将补充平面的字符映射到第零平面(BMP)中的D8-DF码位上,也可以认为是利用这部分空间去代理其他空间的字符。在D8-DF中,D800-DBFF被称为高代理区,DC00-DFFF被称为低代理区 。每一个代理区都有1024 个码位,这两个区可以组成一个二维空间,共有10241024=1048576=1665536个码位。可以发现,这一部分1024*1024的空间刚好可以容纳16个补充平面的所有字符 。
如下图所示,左上角D800 DC00两个代理对代表了字符U+10000,这是第一平面上的第一个字符,右下角DBFF DFFF两个代理对代表了字符U+10FFFF,这是第16平面上的最后一个字符,也就是说,从第一平面到第十六平面的所有字符都被包括进了这张表中。还需要说明一点,下表中行和列的范围都是 ,而不是1-1024。
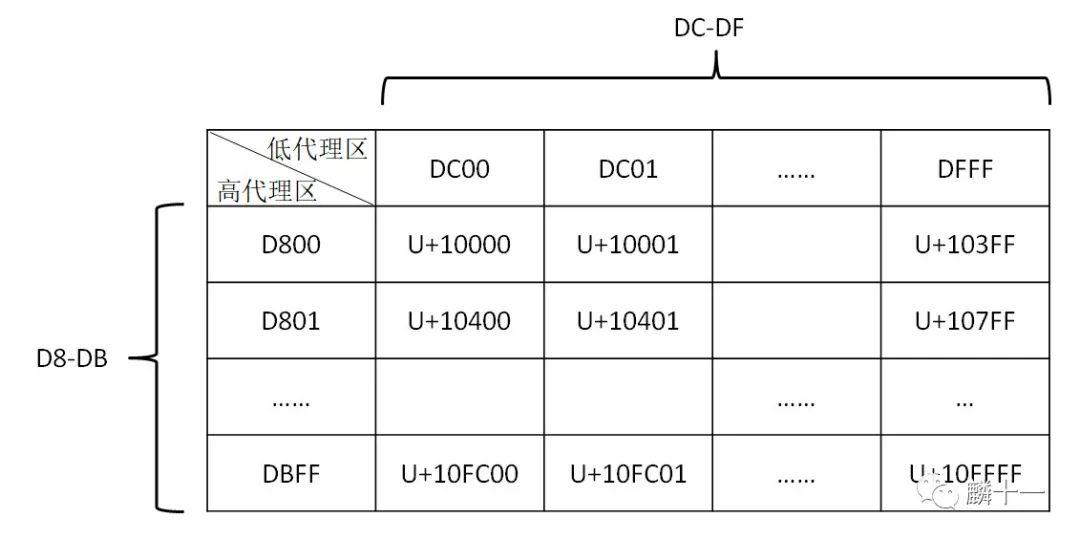
一维代理区转换成二维示意图
接下来让我们换一个视角来解释UTF-16编码,首先令补充平面字符的Unicode十六进制码减去0x10000(65536),意味着将补充平面的内容映射到BMP上,这也是前文uuuuu-1=wwww的含义。减去0x10000后补充平面的码点就被映射在了D8-DF这部分空间内。根据上图可以发现,码点除以0x400(1024)之后,结果的整数部分就是行数(高代理),余数部分就是列数(低代理) 。例如上图中的U+10400,减去0x10000结果为0x400,0x400除以0x400为1,余数为0,说明U+10400在表中的第2行第1列 。
计算完了表中的行列数,需要再加上行和列的起始值 才能得到字符在BMP平面上真正的位置,给行数加上0xD800,列数加上0xDC00 ,得到的两个十六进制数就是UTF-16的编码,高代理对表示前两个字节(第一个码元),低代理对表示后两个字节 (第二个码元)。用公式表示就是:
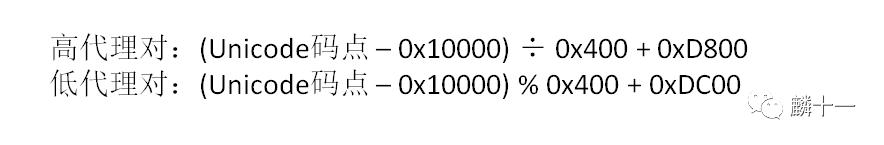
UTF-16编码公式
使用Python计算一下,结果和10.3中相同:
#自定义一个打印函数
def Surrogates(char):
'''输出Unicode字符两个十六进制代理对和二进制数值'''
#高代理,int保留整数
High = int((char - 0x10000) / 0x400 + 0xD800)
High_16 = hex(High)
#低代理
Low = (char - 0x10000) % 0x400 + 0xDC00
Low_16 = hex(Low)
print('代理对: 高代理={} 低代理={}'.format(High_16, Low_16))
print('码元1: {}'.format(bin(int(High_16, 16))[2:]) + '\n' +
'码元2: {}'.format(bin(int(Low_16, 16))[2:]))
#1. Emoji 😄
Surrogates(0x1F604)
#代理对: 高代理=0xd83d 低代理=0xde04
#码元1: 1101100000111101
#码元2: 1101111000000100
#2. CJK兼容象形文字 飢
Surrogates(0x2FA02)
#代理对: 高代理=0xd87e 低代理=0xde02
#码元1: 1101100001111110
#码元2: 110111100000001010.4 UTF-32
最后说一说UTF-32的编码方式,和UTF-8和UTF-16变长编码方式相比,UTF-32是定长 的编码方式,所有的字符都由32bit(4字节)表示,转换时只需要将Unicode十六进制转换成二进制 ,然后高位补0补足32位 即可。UTF-32编码方式最为简单,但是也最占用空间,而且与ASCII也不兼容 。
还是拿“麟”-“U+9E9F ”举例,十六进制转换为二进制是1001(9) 1110(E) 1001(9) 1111(F),共16位,将32位中的高16位全都补为0就得到了UTF-32BE编码。使用Python验证一下(这里我们直接使用10.2中定义的函数Printbyte()即可)
Printbyte('麟', '`utf-32`BE')
#1 编码内容 b'\x00\x00\x9e\x9f'
#2 编码字节长度 4
#3 每字节二进制内容
#第1字节: 00000000 第2字节: 00000000 第3字节: 10011110 第4字节: 10011111整体来说,目前使用最广泛的是 ,有大约96.6% 的网站都在使用这种编码方式,来看一下目前各种编码方式的使用情况,来源 _https://w3techs.com/technologies/overview/character_encoding_
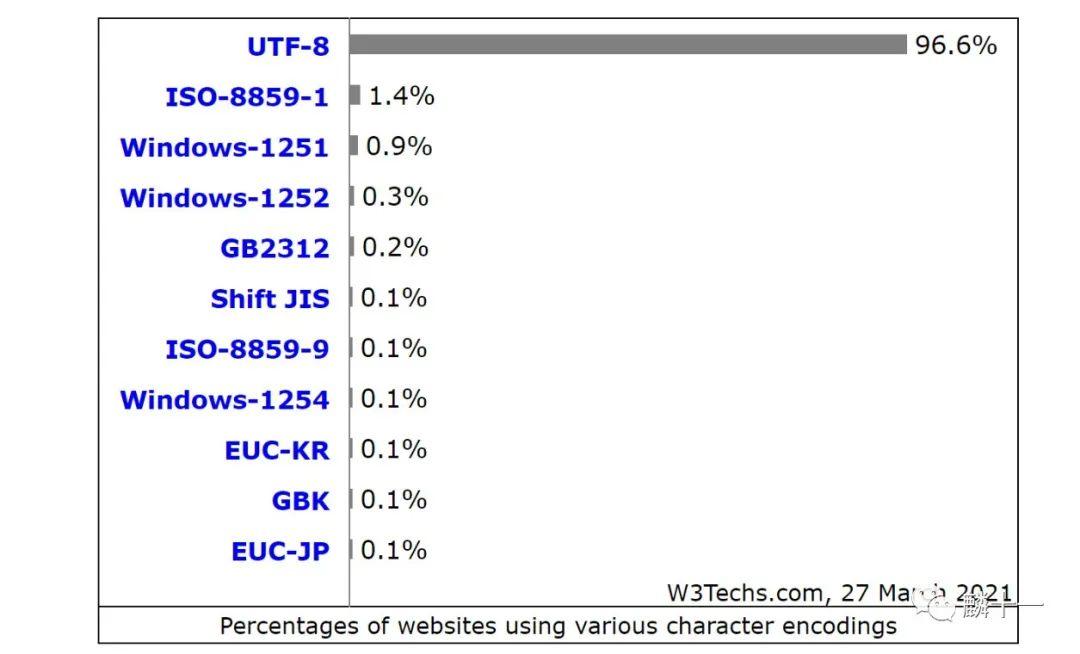
各种编码方式使用情况
11. BOM
 第三阶段:全球化--BOM
第三阶段:全球化--BOM
11.1 BOM
在刚刚使用Python进行UTF-16和UTF-32编码的时候,我使用了UTF-16BE和UTF-32BE,这部分就来讲一讲有关LE,BE和字节序的问题。字节顺序标记(Byte Order Mark, BOM)一般会出现在文件头部,Unicode编码中会使用字节序来标识文件采用哪一种方式进行编码 。不同的编码方式会有不同的BOM,具体如下表所示:
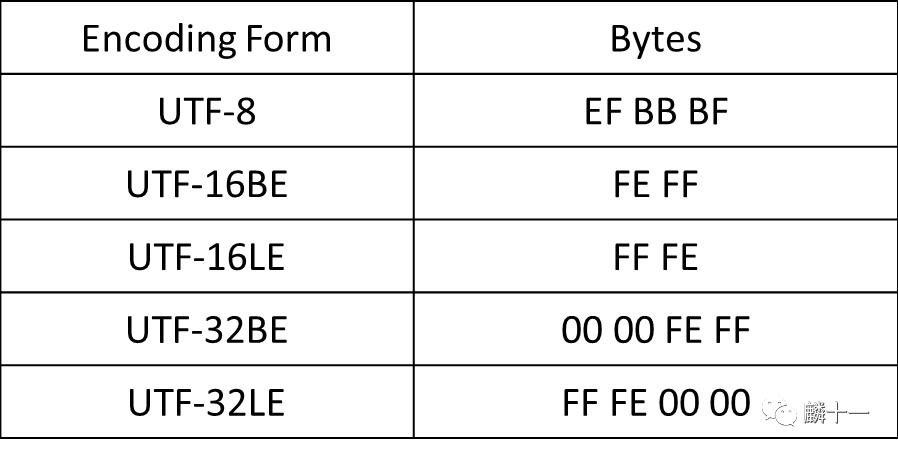 不同编码的BOM表
不同编码的BOM表
可以发现BOM就是Unicode中的码点“U+FEFF ”,在UTF-8中字节序是冗余的 ,在10.3讲到UTF-16代理对的时候我们提到过码元的概念,UTF-8的码元是8bit,也就是单字节码元,而字节序是针对多字节码元的 。我们在使用UTF-8编码的时候,第一个码元序列中的高n位就指明了这个字符有多少个字节,例如“麟”的第一个码元序列高3位是1,说明“麟”使用UTF-8编码会有3个字节,再来看一遍这个图:
UTF-8编码示意表
所以UTF-8并不需要通过BOM来告诉计算机一串数值是使用哪一种方式编码的。但是UTF-16和UTF-32没有这样的标识,只能使用BOM来指明字符的编码方式。BE和LE分别为大端字节序(Big Endian) 和小端字节序(Low Endian) ,指的是计算机读取字节的方向或顺序 ,在面对多字节码元时,计算机可以从高位字节开始读取,也可以从低位字节开始读取,这就产生了两种不同的读取方式。
11.2 BE和LE
刚刚提到,在计算机中有两种读取字节的方式,从高位字节开始读取和从低位字节开始读取。在第2节讲ASCII的时候,我们第一次提到了bit中高位和低位的概念,在ASCII中,低7位被使用,最高位为0。在bit中,低位- >高位 = 右->左。在多字节码元中也是一样的,低字节- >高字节 = 右->左。
而在电脑中地址存储 的顺序是相反的,低地址- >高地址=左->右。大端存储(BE)就是将高位字节存储在电脑中的低地址中,小端存储(LE)就是将高位字节存储在电脑中的高地址中 。来看两张图,还是以“麟”-“U+9E9F”为例。先是大端存储:
 “麟”十六进制大端存储示意图** **
“麟”十六进制大端存储示意图** **
这很符合我们从左至右的阅读习惯,但是从字节的角度来说,属于反向读取和存储。从上图可以看到,UTF-16BE的编码结果是0x9E0x9F ,再来看小端存储:
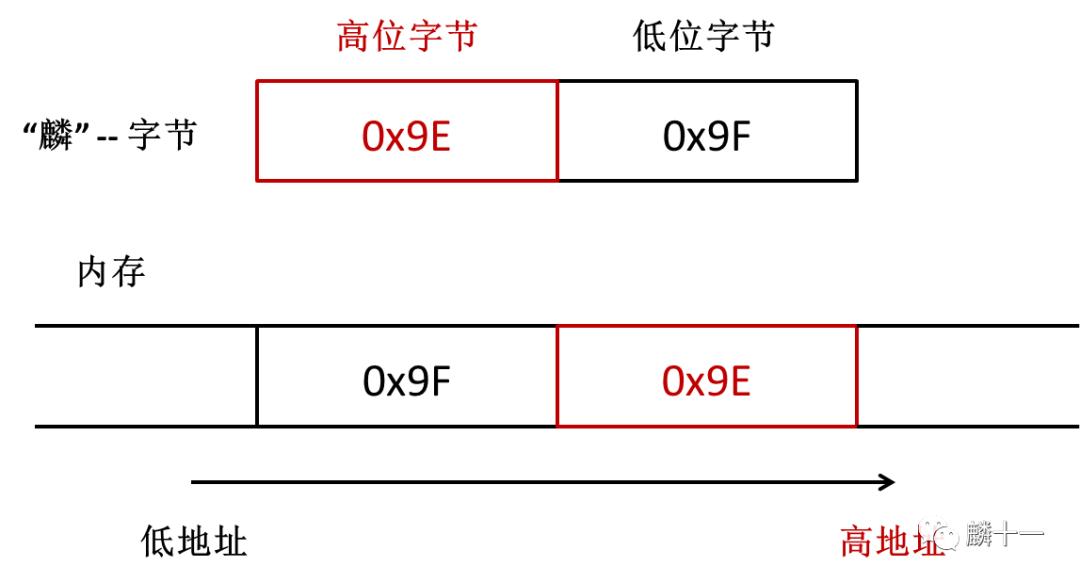
“麟”十六进制小端存储示意图
小端存储对于字节来说是顺序读取和存储,但从我们阅读习惯来看,相当于字节被反向存储了。UTF-16LE对字符编码的结果是0x9F0x9E 。使用Python验证一下,顺便将UTF-32也一并实现了,二者原理相同,就不再展开说明了:
#1. `UTF-16`
'麟'.encode('`utf-16`') # b'\xff\xfe\x9f\x9e'
'麟'.encode('`utf-16`BE') # b'\x9e\x9f'
'麟'.encode('`utf-16`LE') # b'\x9f\x9e'
#1. `UTF-32`
'麟'.encode('`utf-32`') # b'\xff\xfe\x00\x00\x9f\x9e\x00\x00'
'麟'.encode('`utf-32`BE') # b'\x00\x00\x9e\x9f'
'麟'.encode('`utf-32`LE') # b'\x9f\x9e\x00\x00'11.3 utf-8-sig
最后再说一点有关utf-8-sig的问题,11.1中我们提到过在UTF-8中BOM是冗余的,但是目前Windows系统还是可以使用带BOM的UTF-8编码方式对文件进行编码。我在之前读取txt文件的时候就遇到过这种问题,读取出来的字符串开头会带着“\ufeff ”。遇到这种文件可以使用 来解码,sig是signature 的简写,utf-8-sig就是带有签名的UTF-8(UTF-8 with BOM)。我们使用Python对“麟”进行两种方式的编码:
'麟'.encode('`utf-8`')
# b'\xe9\xba\x9f'
'麟'.encode('`utf-8`-sig')
# b'\xef\xbb\xbf\xe9\xba\x9f'可以发现使用utf-8-sig编码会比utf-8多三个字节EF BB BF ,这就是11.1中提到过的UTF-8的BOM。在我们保存TXT文件的时候,可以避免使用带BOM的UTF-8编码方式,而且我们也可以根据需要选择其他编码方式。下图就显示了5种编码方式,还记得吗上一篇的7.4中提到过,Windows系统中,ANSI代表GBK编码
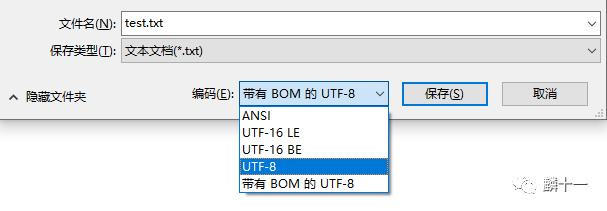
Windows系统对TXT编码
12. Unicode和各种进制的互转
最后的最后,说一下使用Python转换Unicode字符和各种进制的函数。下面一张图就可以概括了,所有进制转换为十进制时都可以用int(str, x) ,x代表原本的进制数,这里的str是字符串格式 。0b,0x和0o分别是二进制,十六进制和八进制的标识符:
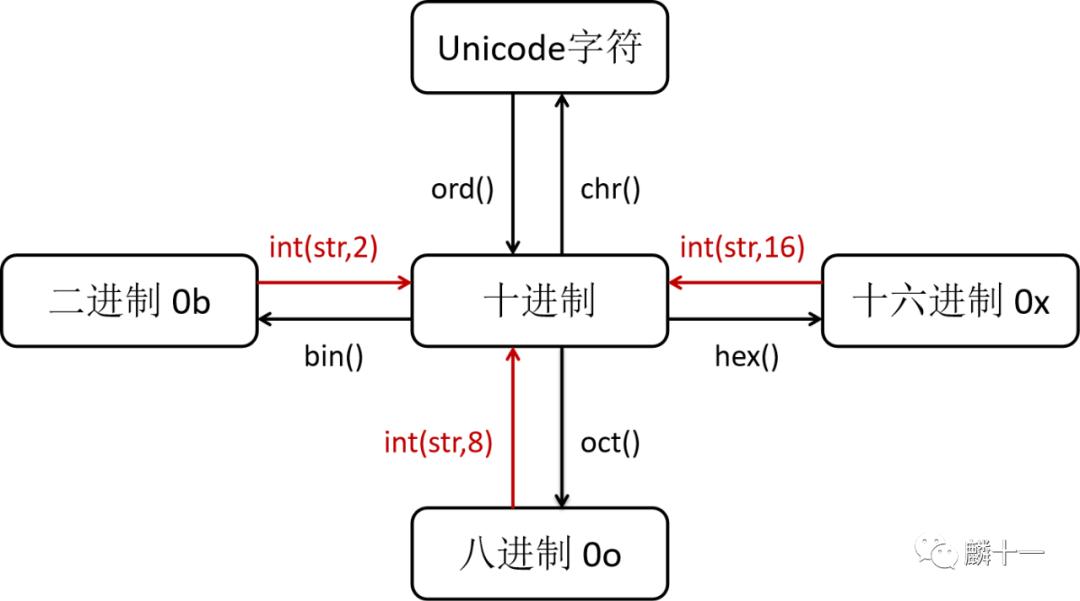 Unicode和进制互转示意图
Unicode和进制互转示意图
使用Python对“麟”转换一下:
#字符 --> Unicode十六进制
hex(ord('麟')) # '0x9e9f'
#Unicode十六进制 --> 字符
chr(int('0x9E9F', 16)) # '麟'推荐两个文章,这是我觉得讲字符编码讲得比较详细的: _https://www.crifan.com/files/doc/docbook/char_encoding/release/html/char_encoding.html_ 和 _https://zhuanlan.zhihu.com/p/27012715_
写在最后
这一篇基本上把字符编码的概念都涵盖到了,当然还是有一些内容没有写到,不过我已经尽力写到详细了。刚开始总觉得Unicode挺简单,后来越查资料越觉得复杂,一个概念接一个概念,就和拆套娃一样等到终于把所有概念都理解清楚了,写文章又是另一个麻烦事,就和把乱七八糟的套娃重新套上一样这种学习方式被我称为“套娃式学习法”。 这一次也是10000+字的长篇,我发现我现在貌似不写到一万字都不会停笔???真的累了,每次写完一篇我都感觉电量耗尽,再也不想写了,但过一阵子又觉得是不是该总结一下学习内容了?这就叫做“循环套娃式写作法”。整体来说,我对于这两篇依旧很满意期待下一篇,也就是真正的”TTF里都有什么“
~END~